提醒: 本篇文章的code在這裡
所謂自然語言處理,就是希望可以讓電腦讀懂人類的文字。不過,這篇文章只會處理已經存成文字檔的文字,暫時不會提到手寫文字辨識、語音辨識、翻譯等功能。而單單處存成文字檔的文字,你或許很難理解,讓電腦讀懂有什麼用處,大約有以下可能的發展方向。
如果大家有注意到,這篇文章講的是英文的自然語言處理。之所以要分開來說是因為中英文的自然語言處理技術,在基礎上面困難點有很大的不同。英文自然語言處理技術上,比較難的是stemming,也就是把started變成start或是把eats變成eat,不過目前套件表現就已經滿不錯了。中文的主要難點在tokenize(斷詞),由於中文詞彙變化多端,也不像英文直接用空白鑑分隔,所以斷詞上必須透過一些演算法去處理,套件的使用上開源社群比較常使用jieba,聽說中研院有做一套出來,但是幾次聽了相關領域的老師或是講者的反饋,大多
import pandas as pd
import nltk
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
from nltk.corpus import stopwords
stops = stopwords.words('english')
from string import punctuation
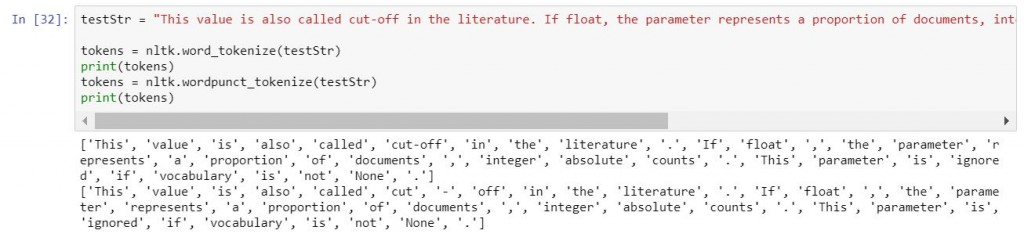
這個動詞的意思就是,把一個句子拆成一個個的單字。以下示範nltk中的兩種tokenize的方式。
testStr = "This value is also called cut-off in the literature. If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None."
tokens = nltk.word_tokenize(testStr)
print(tokens)
tokens = nltk.wordpunct_tokenize(testStr) ## 請注意,差異在cut-off
print(tokens)
stemming和lemmatize是一個把所有不同時態或是不同變化相同的字變成同一個字。而stemming比較像是去掉ed或是s這種添加在字後面的小字母,lemmatize則是字根化,就是把字還原到字根的型態。以下讓我們來看一下示範。
df = pd.DataFrame(index = tokens)
df['porter_stemmer'] = [porter_stemmer.stem(t) for t in tokens]
df['lancaster_stemmer'] = [lancaster_stemmer.stem(t) for t in tokens]
df['snowball_stemmer'] = [snowball_stemmer.stem(t) for t in tokens]
df['wordnet_lemmatizer'] = [wordnet_lemmatizer.lemmatize(t) for t in tokens]
df
| porter_stemmer | lancaster_stemmer | snowball_stemmer | wordnet_lemmatizer | |
|---|---|---|---|---|
| This | Thi | thi | this | This |
| value | valu | valu | valu | value |
| is | is | is | is | is |
| also | also | also | also | also |
| called | call | cal | call | called |
| cut | cut | cut | cut | cut |
| - | - | - | - | - |
| off | off | off | off | off |
| in | in | in | in | in |
| the | the | the | the | the |
| literature | literatur | lit | literatur | literature |
| . | . | . | . | . |
| If | If | if | if | If |
| float | float | flo | float | float |
| the | the | the | the | the |
| parameter | paramet | paramet | paramet | parameter |
| represents | repres | repres | repres | represents |
| a | a | a | a | a |
| proportion | proport | proport | proport | proportion |
| of | of | of | of | of |
| documents | document | docu | document | document |
| integer | integ | integ | integ | integer |
| absolute | absolut | absolv | absolut | absolute |
| counts | count | count | count | count |
| . | . | . | . | . |
不過在前處理上,我們除了會使用tokenize配上stemming或是lemmatize之外,還會把英文字轉乘小寫,看句子的長度決定要不要把停用字跟標點符號拿掉。
| | | | | | | | | |
|---------|-----------|-------------|----------|---------|---------|----------|------------|-------------|--------
| i | me | my | myself | we | our | ours | ourselves | you | your
| yours | yourself | yourselves | he | him | his | himself | she | her | hers
| herself | it | its | itself | they | them | their | theirs | themselves | what
| which | who | whom | this | that | these | those | am | is | are
| was | were | be | been | being | have | has | had | having | do
| does | did | doing | a | an | the | and | but | if | or
| because | as | until | while | of | at | by | for | with | about
| against | between | into | through | during | before | after | above | below | to
| from | up | down | in | out | on | off | over | under | again
| further | then | once | here | there | when | where | why | how | all
df = pd.DataFrame(index = [t for t in tokens if t not in stops])
df['porter_stemmer'] = [porter_stemmer.stem(t.lower()) for t in tokens if t not in stops]
df['lancaster_stemmer'] = [lancaster_stemmer.stem(t.lower()) for t in tokens if t not in stops]
df['snowball_stemmer'] = [snowball_stemmer.stem(t.lower()) for t in tokens if t not in stops]
df['wordnet_lemmatizer'] = [wordnet_lemmatizer.lemmatize(t.lower()) for t in tokens if t not in stops]
df
| porter_stemmer | lancaster_stemmer | snowball_stemmer | wordnet_lemmatizer | |
|---|---|---|---|---|
| This | thi | thi | this | this |
| value | valu | valu | valu | value |
| also | also | also | also | also |
| called | call | cal | call | called |
| cut | cut | cut | cut | cut |
| literature | literatur | lit | literatur | literature |
| If | if | if | if | if |
| float | float | flo | float | float |
| parameter | paramet | paramet | paramet | parameter |
| represents | repres | repres | repres | represents |
| proportion | proport | proport | proport | proportion |
| documents | document | docu | document | document |
| integer | integ | integ | integ | integer |
| absolute | absolut | absolv | absolut | absolute |
| counts | count | count | count | count |
df_tag = pd.DataFrame(index = tokens)
df_tag['default'] = nltk.pos_tag(tokens)
df_tag['universal'] = nltk.pos_tag(tokens, tagset='universal')
df_tag
| default | universal | |
|---|---|---|
| This | DT | DET |
| value | NN | NOUN |
| is | VBZ | VERB |
| also | RB | ADV |
| called | VBN | VERB |
| cut | VBN | VERB |
| - | : | . |
| off | RB | ADV |
| in | IN | ADP |
| the | DT | DET |
| literature | NN | NOUN |
| . | . | . |
| If | IN | ADP |
| float | NN | NOUN |
| ",","," | . | |
| the | DT | DET |
| parameter | NN | NOUN |
| represents | VBZ | VERB |
| a | DT | DET |
| proportion | NN | NOUN |
| of | IN | ADP |
| documents | NNS | NOUN |
| integer | NN | NOUN |
| absolute | NN | NOUN |
| counts | NNS | NOUN |
| . | . | . |



 iThome鐵人賽
iThome鐵人賽